10 Essential PyTorch Elements in RNNs
By Rajesh Kumar Reddy Avula
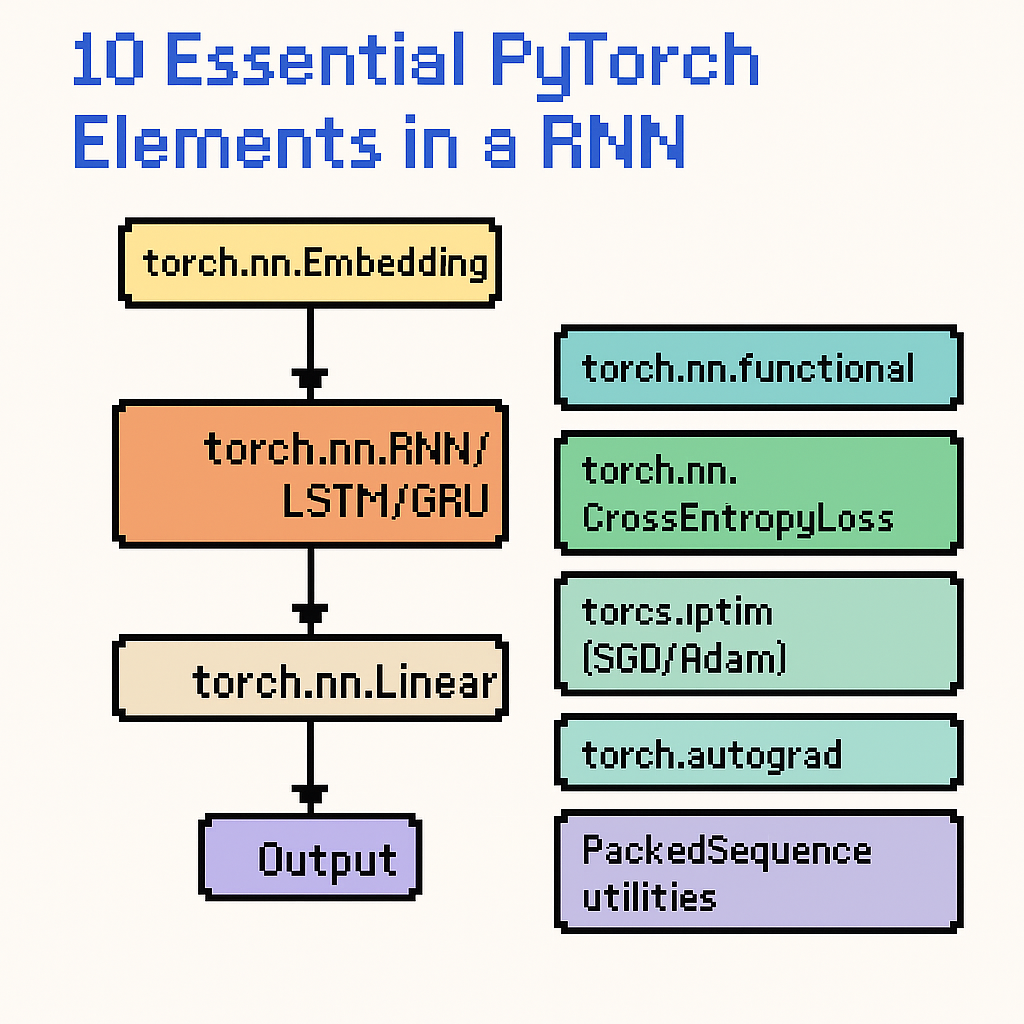
Recurrent Neural Networks (RNNs) are a cornerstone of sequence modeling in PyTorch, powering applications like natural language processing, speech recognition, and time-series forecasting. Learn how these 10 core PyTorch elements simplify RNN development and explore them further in the official documentation here.
Key Insights on PyTorch RNN Elements
These elements form the backbone of RNN construction and training in PyTorch:
- torch.nn.RNN: The base recurrent layer for handling sequential inputs.
- torch.nn.LSTM: Handles long-term dependencies and avoids vanishing gradients.
- torch.nn.GRU: A lightweight alternative to LSTMs with fewer parameters.
- torch.nn.Embedding: Maps discrete tokens to dense vectors in NLP tasks.
- torch.nn.Linear: Fully connected layers applied to recurrent outputs.
- torch.nn.functional: Provides essential activations (ReLU, tanh, softmax).
- torch.nn.CrossEntropyLoss: Standard loss for classification problems.
- torch.optim (SGD/Adam): Updates weights efficiently during training.
- torch.autograd: Powers automatic differentiation for backpropagation.
- PackedSequence utilities: Handle variable-length sequences with `pack_padded_sequence` and `pad_packed_sequence`.
Exploring RNNs Further
Introduced as early solutions to sequential learning problems, PyTorch RNN modules empower developers to create dynamic, modular architectures that adapt to changing data requirements. For hands-on learning, explore the sequence models tutorial.
PyTorch’s design eliminates the need for manual gradient computation. By combining embeddings, recurrent layers, and optimization tools, developers can build scalable and adaptive models that replace traditional rule-based or manual feature engineering approaches.
Developers can easily integrate pretrained embeddings, fine-tuned recurrent layers, and efficient optimizers to deploy pipelines for applications like sentiment analysis, predictive maintenance, or machine translation.
In Real-World Applications
Organizations leverage PyTorch RNNs for diverse use cases, including chatbots, recommendation systems, and anomaly detection. Their modularity allows quick adaptation and scaling to evolving requirements.
Why These 10 Elements Matter
- Versatility: Choose between RNNs, LSTMs, or GRUs for different sequence lengths and complexities.
- Flexibility: Mix embeddings, linear layers, and activations to create custom workflows.
- Scalability: Packed sequences and optimizers let you train on large datasets efficiently.
- Ease of Training: Autograd and CrossEntropyLoss streamline backpropagation and error minimization.
These 10 elements form the foundation of RNN-based modeling in PyTorch, empowering developers to build intelligent, production-ready pipelines for sequential data.
Go backHome